The Fundamentals of Data Engineering - Preface + Chapter 1: Data Engineering Described

This post summarizes the beginning of the book “Fundamentals of Data Engineering” by Joe Reis and Matt Housley. I recently delivered a talk on this info via Taro. The talk for Chapter 2 is happening on February 18. Looking forward to seeing you there!
Without further ado, let’s get right into it.
Preface
In the book's preface, the authors describe their motivations for writing it. The authors describe themselves as “recovering data scientists.” By this, they mean that they started off as data scientists, but realized that before companies can do good data science work, they need to do good data engineering work. That is, data engineering precedes and feeds data science. Hence, companies would be wise to adopt the practices in the book if they want to derive value from data to do data science and machine learning.
The Data Science Hierarchy of Needs (with the bolded annotations on the left added by me) shows how you should build up to Data Science and Machine Learning (and the order you should hire):
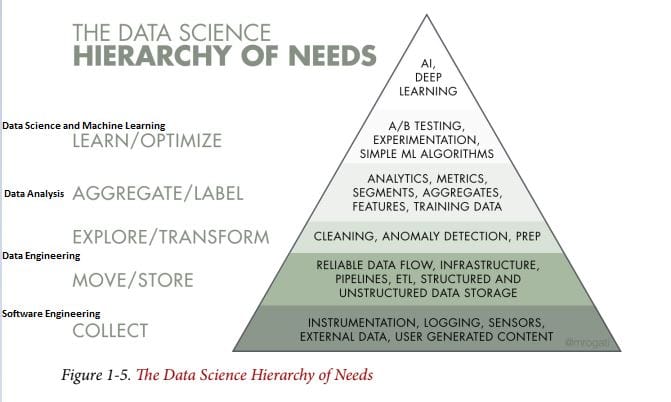
There are 2 principles underlying the whole book:
- The discussion will be on concepts and ideas fundamental to data engineering that encompass any relevant technology
- These concepts will stand the test of time
The book is centered around the Data Engineering Lifecycle, depicted here:

Of the 11 book chapters, the first 4 comprise Part 1: Foundations and Building Blocks, the next 5 comprise Part 2: The Data Engineering Lifecyle in Depth and the last 2 are Part 3: Security, Privacy, and the Future of Data Engineering. Hence, the book is about the above diagram with the heart of the book examining each of the stages of the lifecycle (from Generation to Serving, encompassing Storage) in sequence and in depth.
Before moving on to discuss Chapter 1, I want to mention that I did a poll of the people who attended the Chapter 1 talk, and found most of them were software engineers, not data engineers, analysts or scientists! The takeaway for me is that as ML and AI get more popular and important in the tech world, more people will be interested in data engineering as it is the necessary prerequisite to those fields.
Chapter 1: Data Engineering Described
Chapter 1 is divided into 3 sections: A look at what Data Engineering is, a look at the skills and activities of a Data Engineer, and a look at where a Data Engineer fits in within an organization.
1.1 What is Data Engineering and What is a Data Engineer?
We begin with a definition of Data Engineering: “Data engineering is the development, implementation, and maintenance of systems and processes that take in raw data and produce high-quality, consistent information that supports downstream use cases, such as analysis and machine learning. Data engineering is the intersection of security, data management, DataOps, data architecture, orchestration, and software engineering. A data engineer manages the data engineering lifecycle, beginning with getting data from source systems and ending with serving data for use cases, such as analysis or machine learning.” (FoDE, pg. 4) This definition is essentially word-form of the Data Engineering Lifecycle image I included above. To boil it down even further, we can say Data Engineering takes in data and makes it useful or useable.
1.2 Data Engineering Skills and Activities
The skills a Data Engineer needs to thrive can be divided into business and technical skills. Before looking at those, however, it is important to note that what a Data Engineer does is largely determined by the Data Maturity of the company they are working for. A company can be ‘mature’ or ‘immature’ in its use of data, which will definitely impact the technical work of a Data Engineer. To a lesser but still important extent, it will also impact the business work that a Data Engineer works on.
What does “Data Maturity” mean? The authors define it as “the progression toward higher data utilization, capabilities, and integration across the organization”. In other words, when companies are just getting started with data, they usually are just collecting as much of it as they can and don’t have the processes in place to use all of it, so their “utilization” is low. Conversely, data-mature companies have been collecting and using data for a while, so it is usually easier for them to make use of new data or old data in new ways.
There are 3 stages of Data Maturity:
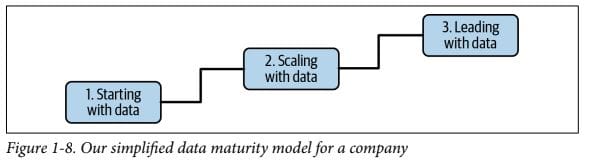
- Starting with data: This stage is characterised by “move fast, get traction, and add value”. At this stage, a company is at the beginning of making data useful, so it’s important that a Data Engineer delivers business value quickly to show executives that data initiatives are worthwhile. Communicating with business on what problems to solve is crucial, as is not complicating solutions to avoid long delivery times.
- Scaling with data: In this stage, the data architecture becomes more advanced. Scale becomes an issue, as initial solutions that delivered value have been proven and so now are subjected to increasing load. In this stage, custom code is often written to supplement off-the-shelf products.
- Leading with data: Here a company has been using data successfully, so there’s less of an emphasis on building and more of one on maintaining. Maintenance involves “enterprisey” aspects of data such as governance (who has access to what data) and quality (how good/reliable/clean is it).
In each of the stages, communicating with business on what problems to solve is paramount, as is keeping solutions as simple as possible.
The above provides a good framework from which to think about the business skills of a Data Engineer. They are:
- Communication: with both technical (e.g. data scientists and software engineers) and non-technical (i.e. business) people
- Scoping and Gathering Business and Product Requirements: For a great blog post on a good check list to run through before creating any pipeline, see here.
- Understanding Agile, DevOps and DataOps: tech methodologies and practices
- Controlling costs: Money (e.g. cloud costs) and Time (e.g. saving business analysts time by automating reports for them)
- Continuous Learning: always lots of new tools to learn!
The main Tech Skills that a Data Engineer needs are:
- SQL: for interfacing with databases and datalakes
- Python: for Data Science work, Backend Engineering work, and scripting (e.g. an AWS Lambda script to pull a file from an API and drop it in an S3 bucket).
- CLI Tools like bash or Powershell: for scripting and OS operations
- A JVM language like Java or Scala
Having listed all those, I will say again that business skills are important than technical skills as having a beautiful solution to a non-existent or minor problem is a waste of time and money.
We conclude this section on data engineer skills and activities by talking about the 2 kinds of Data Engineers. The first is a Type A Data Engineer, where A stands for “Abstraction” or “Analytics”. This Engineer is focused on the data in data engineering and typically uses off-the-shelf products, managed services, and tools rather than custom code. They are found at all companies, but especially companies at Stage 1 of the Data Maturity model who need business value as fast as possible.
The other type of Data Engineer is a Type B Data Engineer where B stands for “Build”. This Engineer is focused on the engineering in Data Engineering, and typically writes custom code to scale and leverage a company’s core competency.
For a more in-depth look at both types, please see this great blog post by Sarah Floris.
1.3 Data Engineers Inside an Organization
We conclude by situating a Data Engineer within an organization along 3 axes: whether they are internal or external facing, who they are upstream and downstream of, and where they fit within business.
The first axis is about whether a Data Engineer is internal or external facing.


An internal-facing Data Engineer will typically create and maintain data pipelines and warehouses for Business Intelligence (BI) reports and dashboards. If the company is more data-advanced, they might also maintain ML pipelines and warehouses. The external-facing data engineer will process transactional and event data coming from outside the business. The key difference is who the stakeholders for the Data Engineer are. External-facing ones directly serve clients. Internal-facing ones serve business and internal stakeholders. Most Data Engineers are internal-facing ones.
Next we situate a Data Engineer among their technical peers:

Upstream to a Data Engineer we have Data Architects and Software Engineers. Together, they define the kind of data a Data Engineer has to work with, as well as things like the frequency it arrives. Downstream from a Data Engineer are the Data Analysts, Scientists, and Machine Learning Engineers. They make use of the cleaned-up data a Data Engineer provides to provide insights about the business in the past (Analyst), present (Analyst), or future (Scientist) and to deploy machine learning models that operationalize those insights (ML Engineers).
Finally, we situate a Data Engineer within the business. Data Engineers may work with executives in the C-suite, including the CEO, on critical business initiatives like cloud migrations or new data systems. More generally, they may speak with these people to make them aware of what can and can’t be done with data (sometimes difficult conversations indeed). For less critical projects, Data Engineers will work with projects managers and product managers, who both ensure projects are on track and engineers are getting the resources they need.
Conclusion
That’s a wrap for the Preface and Chapter 1! Stay tuned for the next blog post on Chapter 2, which will appear around the time of the next talk, happening February 18! Chapter 2 covers The Data Engineering Lifecycle at a high level, so is the single most important chapter in the book.
I’ll see you there!



Comments ()