Paper Reading: An Image is Worth 16x16 Words
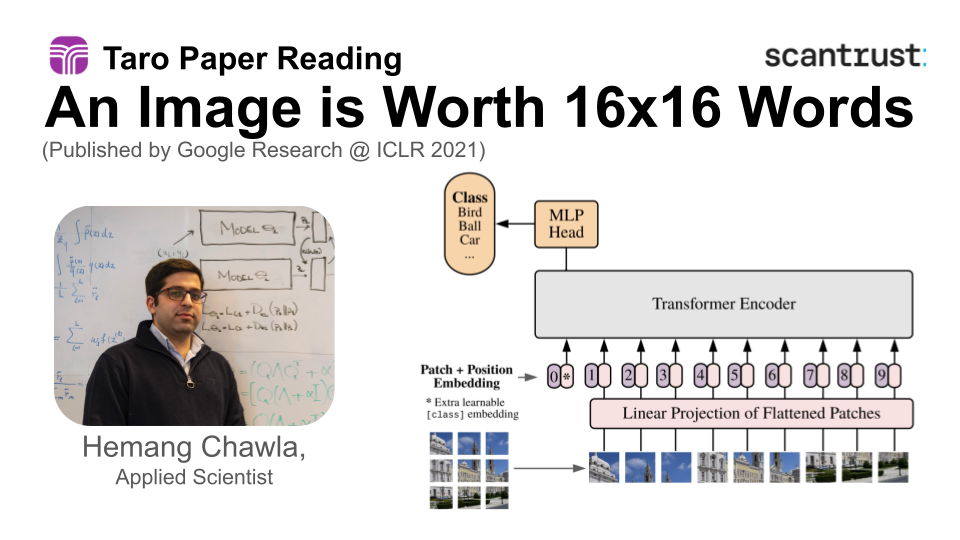
While the transformer architecture was originally introduced for natural language processing, this seminal paper showed how it can be successfully applied for large-scale computer vision problems. Published by Google Research at ICLR 2021, it has been cited over 28,000 times, and has been used as the backbone of several foundational models.
What's in store?
This session is open to all software engineers and welcomes participants with little prior background in the topic. Join us for an accessible introduction to vision transformers.
- Brief intro to transformers
- Vision Transformer (ViT) architecture for Image recognition at scale
- Applications beyond classification
Link to paper: https://iclr.cc/virtual/2021/oral/3458
Your host:
Hemang Chawla is an applied scientist in computer vision focusing on anti-counterfeiting at Scantrust. He has previous worked in the domains of robotics and mapping for ADAS, and has published several papers at top conferences such as ICRA, IROS, and WACV.
This event is free for all. For premium access to Taro, you may use this referral link for a 20% discount.