Find Servers That Handled Most Number of Requests
Find Servers That Handled Most Number of Requests #1 Most Asked
HardYou have k servers numbered from 0 to k-1 that are being used to handle multiple requests simultaneously. Each server has infinite computational capacity but cannot handle more than one request at a time. The requests are assigned to servers according to a specific algorithm:
- The
ith(0-indexed) request arrives. - If all servers are busy, the request is dropped (not handled at all).
- If the
(i % k)thserver is available, assign the request to that server. - Otherwise, assign the request to the next available server (wrapping around the list of servers and starting from 0 if necessary). For example, if the
ithserver is busy, try to assign the request to the(i+1)thserver, then the(i+2)thserver, and so on.
You are given a strictly increasing array arrival of positive integers, where arrival[i] represents the arrival time of the ith request, and another array load, where load[i] represents the load of the ith request (the time it takes to complete). Your goal is to find the busiest server(s). A server is considered busiest if it handled the most number of requests successfully among all the servers.
Return a list containing the IDs (0-indexed) of the busiest server(s). You may return the IDs in any order.
Example 1:
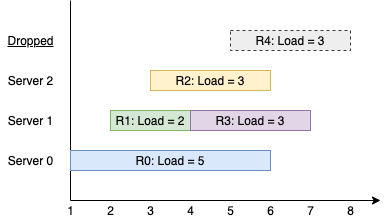
Input: k = 3, arrival = [1,2,3,4,5], load = [5,2,3,3,3] Output: [1] Explanation: All of the servers start out available. The first 3 requests are handled by the first 3 servers in order. Request 3 comes in. Server 0 is busy, so it's assigned to the next available server, which is 1. Request 4 comes in. It cannot be handled since all servers are busy, so it is dropped. Servers 0 and 2 handled one request each, while server 1 handled two requests. Hence server 1 is the busiest server.
Example 2:
Input: k = 3, arrival = [1,2,3,4], load = [1,2,1,2] Output: [0] Explanation: The first 3 requests are handled by first 3 servers. Request 3 comes in. It is handled by server 0 since the server is available. Server 0 handled two requests, while servers 1 and 2 handled one request each. Hence server 0 is the busiest server.
Example 3:
Input: k = 3, arrival = [1,2,3], load = [10,12,11] Output: [0,1,2] Explanation: Each server handles a single request, so they are all considered the busiest.
Constraints:
1 <= k <= 1051 <= arrival.length, load.length <= 105arrival.length == load.length1 <= arrival[i], load[i] <= 109arrivalis strictly increasing.
Solution
Clarifying Questions
When you get asked this question in a real-life environment, it will often be ambiguous (especially at FAANG). Make sure to ask these questions in that case:
- If a server's task finishes at the exact same moment a new request arrives, is that server considered available to handle the new request?
- To clarify the wrap-around logic: if the target server `i % k` for the i-th request is busy, is the next server to check `(i % k + 1) % k`, then `(i % k + 2) % k`, and so on?
- The finish times for requests can be as large as 2 * 10^9, which is close to the 32-bit integer limit. Should I use 64-bit integers for time calculations to prevent any potential overflow issues?
- When a request is dropped because all servers are busy, is it correct to assume that it's permanently discarded and has no further effect on the system or subsequent requests?
- If no requests are handled by any server (a case which seems impossible since the first request should always succeed), what should the output be?
Brute Force Solution
Approach
The straightforward approach is to act like a dispatcher, simulating the entire process in order. We will look at each request as it arrives and check the servers one by one, following the specific assignment rules to see which one is free to handle the work.
Here's how the algorithm would work step-by-step:
- First, imagine all your servers are idle and ready to work. We'll also keep a scorecard for each server, starting at zero, to count how many requests each one completes.
- Begin by taking the first request from the incoming list.
- Before trying to assign this request, update the status of all servers. Any server that was busy but scheduled to finish its task before this new request arrived is now considered free.
- Now, to find a home for the current request, the rules point to a specific server to start your search with.
- Check if that starting server is free. If it is busy, check the next server in the line, and then the next, wrapping around to the beginning of the line if you reach the end.
- Continue this search until you find a free server. Once you find one, assign the request to it, add one to that server's score, and make a note of when it will become free again.
- If you circle through all the servers and find that every single one is busy, then the request has to be dropped.
- Repeat this entire process for every single request, one after the other, in the order they arrive.
- After you've processed all the requests, look at the final scores on the scorecard for every server.
- Find the highest score achieved, and your answer is the list of all the servers that reached that top score.
Code Implementation
def findBusiestServers(number_of_servers, arrival_times, request_loads):
requests_handled_count = [0] * number_of_servers
server_free_time = [0] * number_of_servers
# We must process each request sequentially to accurately mimic the real-time arrival and assignment.
for request_index in range(len(arrival_times)):
current_arrival_time = arrival_times[request_index]
current_request_load = request_loads[request_index]
starting_server_to_check = request_index % number_of_servers
# To follow the round-robin rule, we check servers starting from a preferred index and wrap around.
for server_check_offset in range(number_of_servers):
current_server_to_check = (starting_server_to_check + server_check_offset) % number_of_servers
if server_free_time[current_server_to_check] <= current_arrival_time:
requests_handled_count[current_server_to_check] += 1
server_free_time[current_server_to_check] = current_arrival_time + current_request_load
break
# After simulation, find the maximum load and identify all servers that achieved this load.
max_requests_handled = 0
if requests_handled_count:
max_requests_handled = max(requests_handled_count)
busiest_servers = []
for server_id in range(number_of_servers):
if requests_handled_count[server_id] == max_requests_handled:
busiest_servers.append(server_id)
return busiest_serversBig(O) Analysis
Optimal Solution
Approach
The core idea is to cleverly manage two groups of servers: those that are available and those that are busy. By keeping the available servers sorted by their number and the busy servers sorted by when they finish their tasks, we can instantly find the right server for each new request without wasting time checking them one by one.
Here's how the algorithm would work step-by-step:
- Start by creating two conceptual lists: one for all the available servers and another for the busy ones. Initially, all servers are in the 'available' list, kept in numerical order.
- Go through the incoming requests one at a time.
- For each new request, first look at your 'busy' list. Any server that has finished its task by the time this new request arrives is moved back into the 'available' list.
- Keeping the 'busy' list organized by which server will finish first makes this check very fast.
- Next, figure out the preferred server for the current request based on its position in the overall sequence of requests.
- Look in the 'available' list for a server with a number that is the same as or the next one up from the preferred server's number. If you reach the end of the available servers, just circle back and take the first one available from the beginning of the list.
- If you find an available server, assign the request to it. Add one to that server's personal request count, and move it from the 'available' list to the 'busy' list, noting when it will become free again.
- If there are no available servers at all, the request is simply ignored.
- After you've gone through all the requests, find the highest request count achieved by any server. The final answer is the list of all servers that reached this maximum count.
Code Implementation
import heapq
def busiestServers(number_of_servers, arrival_times, load_times):
server_request_counts = [0] * number_of_servers
busy_servers_by_finish_time = []
# To efficiently find the server, we split available ones into two heaps based on the target.
available_servers_ge_target = list(range(number_of_servers))
available_servers_lt_target = []
for request_index, arrival_time in enumerate(arrival_times):
target_server = request_index % number_of_servers
if target_server == 0:
while available_servers_lt_target:
heapq.heappush(available_servers_ge_target, heapq.heappop(available_servers_lt_target))
# As the target advances, rebalance by moving servers that are now less than the target.
while available_servers_ge_target and available_servers_ge_target[0] < target_server:
server_to_move = heapq.heappop(available_servers_ge_target)
heapq.heappush(available_servers_lt_target, server_to_move)
# Before assigning the request, free up servers that finished their tasks.
while busy_servers_by_finish_time and busy_servers_by_finish_time[0][0] <= arrival_time:
finish_time, freed_server_index = heapq.heappop(busy_servers_by_finish_time)
if freed_server_index < target_server:
heapq.heappush(available_servers_lt_target, freed_server_index)
else:
heapq.heappush(available_servers_ge_target, freed_server_index)
# Assign request, prioritizing servers >= target, then wrapping around to smallest index.
if available_servers_ge_target:
chosen_server = heapq.heappop(available_servers_ge_target)
elif available_servers_lt_target:
chosen_server = heapq.heappop(available_servers_lt_target)
else:
continue
server_request_counts[chosen_server] += 1
processing_time = load_times[request_index]
new_finish_time = arrival_time + processing_time
heapq.heappush(busy_servers_by_finish_time, (new_finish_time, chosen_server))
max_requests_handled = max(server_request_counts) if server_request_counts else 0
busiest_servers_result = []
for server_index, request_count in enumerate(server_request_counts):
if request_count == max_requests_handled:
busiest_servers_result.append(server_index)
return busiest_servers_resultBig(O) Analysis
Edge Cases
| Case | How to Handle |
|---|---|
| All requests are dropped due to very long server loads, leaving all servers with a zero request count. | The solution correctly identifies an empty pool of available servers, resulting in all servers being returned as the busiest. |
| Only one server is available to handle all requests (k=1). | The standard assignment logic naturally handles this case as the target server index `i % k` is always 0. |
| The number of servers is greater than the total number of requests, resulting in no server contention. | Each request `i` is assigned to its preferred and always-available server `i`, as `i % k` will be unique for each request. |
| The sum of a request's arrival time and load time exceeds the 32-bit integer limit. | Using 64-bit integer types for storing server finish times prevents overflow and ensures correct temporal comparisons. |
| An assignment search must wrap around because all servers from the target `i % k` to `k-1` are busy. | The search for an available server correctly wraps by finding the smallest server index if no suitable one is found starting from the target. |
| A new request arrives at a time when all k servers are simultaneously occupied. | The set of available servers becomes empty, correctly causing the incoming request to be dropped as per the problem rules. |
| A request arrives at the exact moment a server completes its previous task. | The logic first frees all servers whose tasks complete by or at the current arrival time, making them available for the new request. |
| Multiple servers tie for the maximum number of requests handled. | A final pass over all server request counts collects the IDs of every server that matches the determined maximum count. |