Get Watched Videos by Your Friends #4 Most Asked
MediumThere are n people, each person has a unique id between 0 and n-1. Given the arrays watchedVideos and friends, where watchedVideos[i] and friends[i] contain the list of watched videos and the list of friends respectively for the person with id = i.
Level 1 of videos are all watched videos by your friends, level 2 of videos are all watched videos by the friends of your friends and so on. In general, the level k of videos are all watched videos by people with the shortest path exactly equal to k with you. Given your id and the level of videos, return the list of videos ordered by their frequencies (increasing). For videos with the same frequency order them alphabetically from least to greatest.
Example 1:
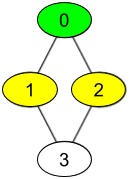
Input: watchedVideos = [["A","B"],["C"],["B","C"],["D"]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 1 Output: ["B","C"] Explanation: You have id = 0 (green color in the figure) and your friends are (yellow color in the figure): Person with id = 1 -> watchedVideos = ["C"] Person with id = 2 -> watchedVideos = ["B","C"] The frequencies of watchedVideos by your friends are: B -> 1 C -> 2
Example 2:

Input: watchedVideos = [["A","B"],["C"],["B","C"],["D"]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 2 Output: ["D"] Explanation: You have id = 0 (green color in the figure) and the only friend of your friends is the person with id = 3 (yellow color in the figure).
Constraints:
n == watchedVideos.length == friends.length2 <= n <= 1001 <= watchedVideos[i].length <= 1001 <= watchedVideos[i][j].length <= 80 <= friends[i].length < n0 <= friends[i][j] < n0 <= id < n1 <= level < n- if
friends[i]containsj, thenfriends[j]containsi
Solution
Clarifying Questions
When you get asked this question in a real-life environment, it will often be ambiguous (especially at FAANG). Make sure to ask these questions in that case:
- Can you please clarify the data types and range of values for the user IDs and video IDs?
- What should I return if a user has no friends, or if none of their friends have watched any videos?
- If multiple videos have the same view count among friends, how should I order them in the output?
- Is the 'level' parameter guaranteed to be non-negative? What happens if the 'level' exceeds the depth of the friendship network?
- Are there any constraints on the size of the user and video lists, or the depth of the friendship network? This might impact memory usage.
Brute Force Solution
Approach
The brute force approach involves exploring all possible friends within the specified levels. For each friend found, collect all the videos they watched and then count how many times each video appears.
Here's how the algorithm would work step-by-step:
- Start with the given person and their list of friends.
- Go through the first level of friends to see who they are.
- Then go through the friends of those friends to find the second level of friends, and so on, up to the specified level.
- As you find each friend, note the videos they have watched.
- Once you have found all friends within the level, create a big list of all the videos watched by those friends.
- Count how many times each video appears in the big list.
- Finally, present the videos sorted by how often they were watched.
Code Implementation
def watched_videos_by_friends_brute_force(watched_videos, friend_connections, person_id, level):
friends_at_level = get_friends_at_level(friend_connections, person_id, level)
watched_videos_by_friends = []
# Iterate through each friend at the specified level.
for friend in friends_at_level:
watched_videos_by_friends.extend(watched_videos[friend])
video_counts = {}
for video in watched_videos_by_friends:
if video in video_counts:
video_counts[video] += 1
else:
video_counts[video] = 1
# Sort videos by frequency and then alphabetically.
sorted_videos = sorted(video_counts.items(), key=lambda item: (item[1], item[0]))
result = [video for video, count in sorted_videos]
return result
def get_friends_at_level(friend_connections, person_id, level):
queue = [(person_id, 0)]
visited = {person_id}
friends_at_target_level = []
while queue:
current_person, current_level = queue.pop(0)
if current_level == level:
friends_at_target_level.append(current_person)
continue
# Traverse the graph breadth first
for friend in friend_connections[current_person]:
if friend not in visited:
visited.add(friend)
queue.append((friend, current_level + 1))
return friends_at_target_levelBig(O) Analysis
Optimal Solution
Approach
The goal is to find videos watched by friends within a certain degree of separation. We'll use a method similar to how information spreads in social networks, focusing on expanding our search layer by layer and keeping track of who watched what.
Here's how the algorithm would work step-by-step:
- Start with the initial person and consider them level zero.
- Find all the people who are directly friends with the initial person (level one friends).
- Repeat this process to find friends of friends (level two friends), then friends of friends of friends (level three friends), and so on, up to the specified degree.
- As you discover each friend, keep track of the videos they have watched.
- Once you've explored all friends within the specified degree of separation, count how many times each video was watched across all those friends.
- Finally, sort the videos by the number of times they were watched, starting with the most popular, and return this list.
Code Implementation
def get_watched_videos_by_friends(watched_videos, friends, person_id, level): video_counts = {}
visited = {person_id}
queue = [(person_id, 0)]
while queue:
current_person, current_level = queue.pop(0)
if current_level <= level:
# Process videos watched by friends within the level
for video in watched_videos[current_person]:
video_counts[video] = video_counts.get(video, 0) + 1
if current_level < level:
# Explore friends of the current person
for friend in friends[current_person]:
if friend not in visited:
visited.add(friend)
queue.append((friend, current_level + 1))
# Avoid returning videos watched by the target
for video in watched_videos[person_id]:
if video in video_counts:
del video_counts[video]
# Sort videos by frequency, then alphabetically
sorted_videos = sorted(video_counts.items(), key=lambda item: (item[1], item[0]))
result = [video for video, count in sorted_videos]
return resultBig(O) Analysis
Edge Cases
| Case | How to Handle |
|---|---|
| Empty watchedVideos or friends lists | Return an empty list if either the watchedVideos or friends lists are empty, as there are no videos to watch or friends to consider. |
| No common friends between user and other users | If no one is a friend of the target user, the algorithm should still return an empty list of videos. |
| Cycle in the friend network | Use a visited set to prevent infinite loops and ensure each friend is only processed once. |
| Very large friend network (scalability) | The solution should use a breadth-first search (BFS) approach, which is suitable for exploring large networks, and minimize memory usage with efficient data structures. |
| watchedVideos list containing null or empty strings | Filter out null or empty strings from the watchedVideos lists to avoid errors during processing or counting. |
| Large number of videos watched by individual friends | Use a hash map to efficiently count the frequency of watched videos, even with a large number of videos per friend. |
| Input level exceeding the number of friends | Return an empty list if the input level is greater than or equal to the number of friends, as there won't be any videos at that level. |
| Integer overflow in frequency counts | Use a data type with sufficient capacity (e.g., long in Java) for the video frequency counts to prevent integer overflows when dealing with a very large number of friends or videos. |