Remove Duplicates from Sorted List
Remove Duplicates from Sorted List #6 Most Asked
EasyGiven the head of a sorted linked list, delete all duplicates such that each element appears only once. Return the linked list sorted as well.
Example 1:
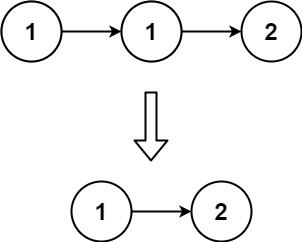
Input: head = [1,1,2] Output: [1,2]
Example 2:

Input: head = [1,1,2,3,3] Output: [1,2,3]
Constraints:
- The number of nodes in the list is in the range
[0, 300]. -100 <= Node.val <= 100- The list is guaranteed to be sorted in ascending order.
Solution
Clarifying Questions
When you get asked this question in a real-life environment, it will often be ambiguous (especially at FAANG). Make sure to ask these questions in that case:
- Can the linked list be empty, or will it always contain at least one node?
- What is the range of values for the nodes in the linked list?
- Is the input list guaranteed to be sorted in ascending order, or do I need to handle unsorted input?
- Should I modify the values of the existing nodes, or can I create new nodes?
- What should I return if the input list is null?
Brute Force Solution
Approach
The brute force method for removing duplicates in a sorted list is like checking every single value against every other value. We painstakingly compare each item to all subsequent items to identify and handle duplicates. It's a thorough but inefficient way to solve the problem.
Here's how the algorithm would work step-by-step:
- Start with the first item in the list.
- Compare it to every item that comes after it in the list.
- If you find an item that is the same, remove the duplicate from the list.
- Move to the next item in the original list.
- Repeat the comparison process, comparing the current item to all the items that follow it.
- Continue this process until you have compared every item to all the items that come after it.
- The result will be a list with all duplicates removed.
Code Implementation
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
def remove_duplicates_brute_force(head):
current_node = head
while current_node:
# Iterate through the rest of the list for each node.
runner_node = current_node
while runner_node.next:
if current_node.val == runner_node.next.val:
# Remove the duplicate node
runner_node.next = runner_node.next.next
else:
runner_node = runner_node.next
# Advance current_node to the next unique node.
current_node = current_node.next
return headBig(O) Analysis
Optimal Solution
Approach
Since the list is sorted, we can solve this problem efficiently by traversing it only once. We just need to keep track of the last unique element we've seen and remove any subsequent duplicates we encounter.
Here's how the algorithm would work step-by-step:
- Begin by examining the first item in the list. This item is, by default, considered a unique item.
- Compare the current item with the next item in the list.
- If the next item is identical to the current item, remove the next item from the list. Continue doing this until you encounter a different item.
- If the next item is different from the current item, move your focus to the next item (the new unique one).
- Repeat steps 2-4 until you reach the end of the list.
Code Implementation
class ListNode:
def __init__(self, value=0, next_node=None):
self.value = value
self.next = next_node
def remove_duplicates_from_sorted_list(head):
if not head:
return head
current_node = head
while current_node.next:
# Compare current node to the next
if current_node.value == current_node.next.value:
# Remove the duplicate node
current_node.next = current_node.next.next
else:
# Move to the next unique node
current_node = current_node.next
return head
Big(O) Analysis
Edge Cases
| Case | How to Handle |
|---|---|
| Empty list (head is null) | Return null immediately as there's nothing to process. |
| List with only one node | Return the head as is, since there are no duplicates possible. |
| List with all nodes having the same value | The algorithm should reduce the list to a single node with that value. |
| List with consecutive duplicate values at the beginning | The algorithm should correctly skip all initial duplicates. |
| List with consecutive duplicate values in the middle | The algorithm should correctly skip all middle duplicates while maintaining the sorted order. |
| List with consecutive duplicate values at the end | The algorithm should correctly remove trailing duplicates and terminate the list properly. |
| Large list (potential performance concerns) | The iterative approach maintains O(n) time complexity, which scales linearly, but recursion could lead to stack overflow. |
| Negative and positive values intermixed with duplicates | Since the list is sorted, the algorithm handles both negative and positive values equally by comparing adjacent nodes. |