Paper Reading: Attention is All You Need (Legendary Google Paper)
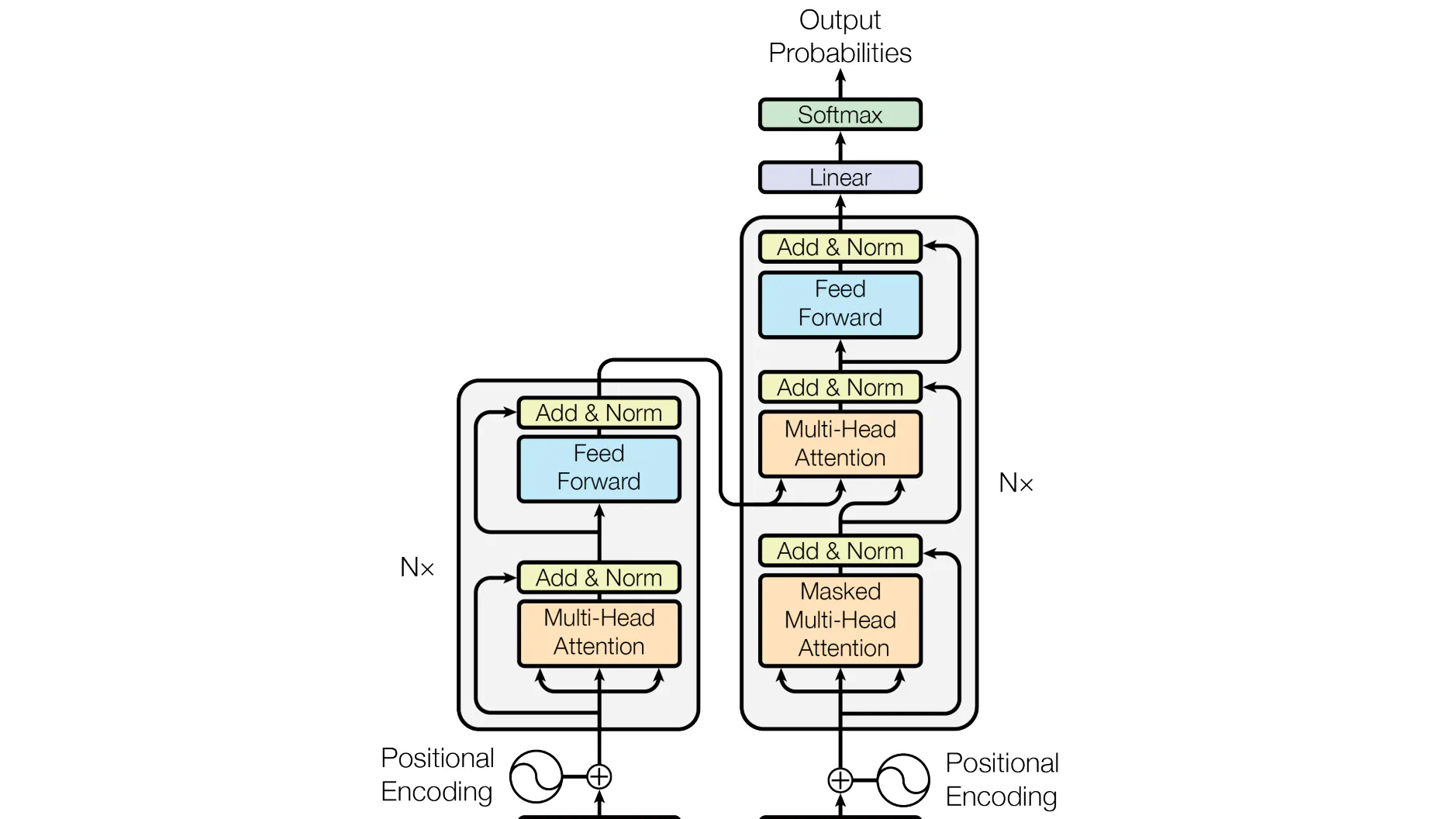
"Attention is All You Need" is a seminal research paper published by researchers at Google in 2017, introducing the Transformer model. The paper revolutionized natural language processing and machine translation by proposing a new architecture that relies solely on self-attention mechanisms, eliminating the need for recurrent or convolutional layers.
This paper and the Transformer model it introduced are crucial in the context of Large Language Models (LLMs) for several reasons:
- Parallelization
- Long-Range Dependencies
- Efficient Attention Mechanism
- Pre-training and Transfer Learning
We will be discussing the internals of the Transformer architecture which will help guide our journey into the LLM space.
Paper link - https://arxiv.org/abs/1706.03762?ref=blog.oxen.ai / Event recording: https://www.jointaro.com/lesson/Inm8iy8RC32KJUNlTM15/paper-reading-attention-is-all-you-need/ / Reach out to Mandar Deshpande for any event related queries.